
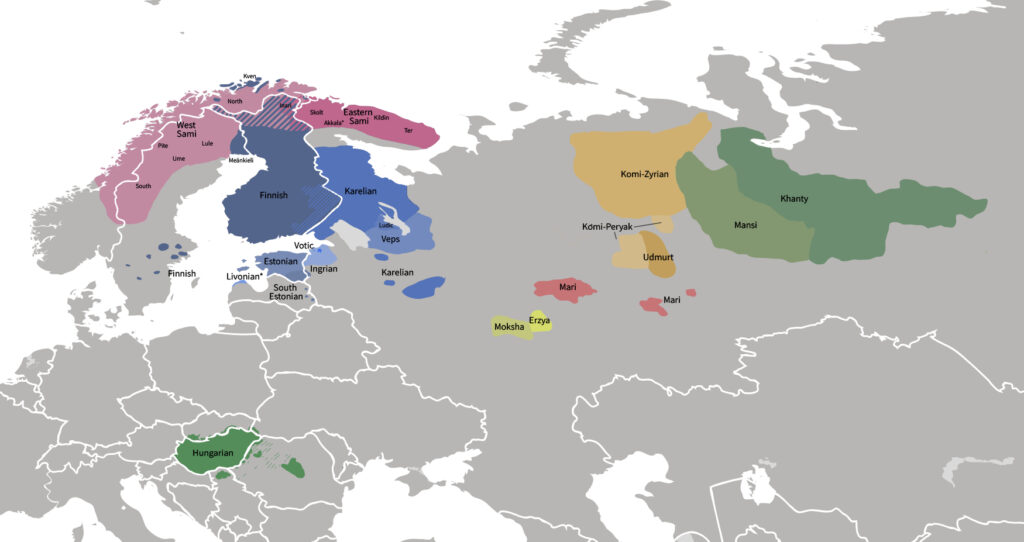
Researchers at the University of Tartu Institute of Computer Science have added Livonian, Komi, Mansi and 14 other Finno-Ugric languages to the university’s machine translation engine.
Most of these languages became available on a public translation engine for the first time, as they are not part of Google Translate and similar services, the university said in a statement.
In total, the translation engine supports 23 Finno-Ugric languages: in addition to the more commonly supported Estonian, Finnish and Hungarian, it now includes Livonian, Võro, Proper Karelian, Livvi Karelian, Ludian, Veps, Northern Sami, Southern Sami, Inari Sami, Skolt Sami, Lule Sami, Komi, Komi-Permyak, Udmurt, Hill Mari and Meadow Mari, Erzya, Moksha, Mansi and Khanty.
The research group invites speakers and researchers of these languages to contribute corrected translations to improve translation quality. This can be done by editing translations at translate.ut.ee. Texts such as poems, articles, books and similar in these languages are also of great help and can be sent to ping@tartunlp.ai.
Lisa Yankovskaya, a research fellow in natural language processing at the University of Tartu Institute of Computer Science, said feedback is needed to improve the translation quality because many of these languages have extremely scarce resources for creating translation systems.

Preserving endangered languages
This means two things – first, the translation quality can vary a lot, and it can be especially low when translating into low-resourced languages. Secondly, the developers need the help of speakers of these languages in the form of contributing correct translations on the platform.
She said there were several reasons for developing machine translation for low-resource languages. For example, philologists and others need the machine translation option to understand texts without learning the language.
Translating into these languages is also a way of preserving endangered languages and supporting the speakers of these languages. This is why the translation system is open to all users and the software and the created models are open source.
The developers started to work with Finno-Ugric languages in 2021, with the first system supporting Võro, Northern Sami and Southern Sami, said Maali Tars, scientific programmer at the Institute of Computer Science. Livonian, an extremely endangered language with just about 20 near-native speakers, was added in the same year. They intend to continue to improve the quality of the machine translation system and include more Finno-Ugric languages and dialects.
The developers worked with the Livonian Institute at the University of Latvia, Võro Institute, the University of Eastern Finland and the Karelian language revitalisation programme of the University of Eastern Finland.
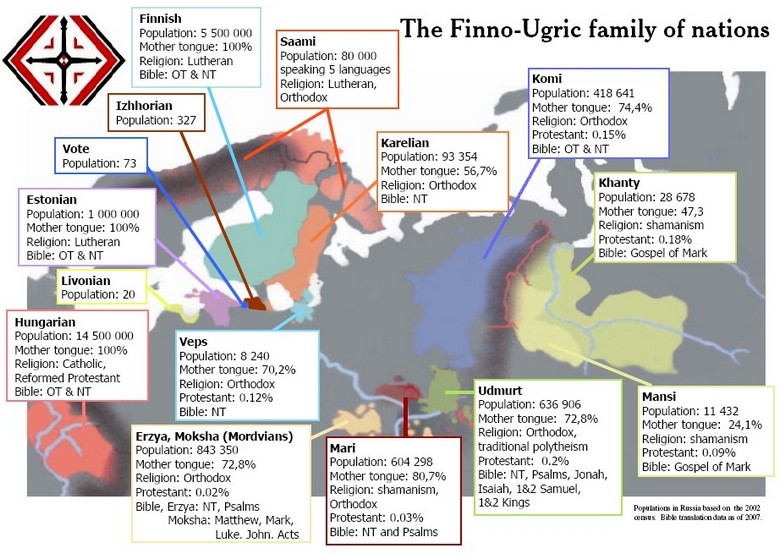
The Finno-Ugric world comprises 25 million people who mostly live in north-east Europe across the Nordic and Baltic regions and Russia. The four most numerous Finno-Ugric peoples are the Hungarians (13-14 million), the Finns (6-7 million), the Estonians (1.1 million) and the Mordvins (740,000). The first three inhabit independent states – Hungary, Finland and Estonia – whereas Mordovia is a republic within Russia.
* The article originally mentioned that the researchers also worked with the Arctic University of Norway; this is not the case.